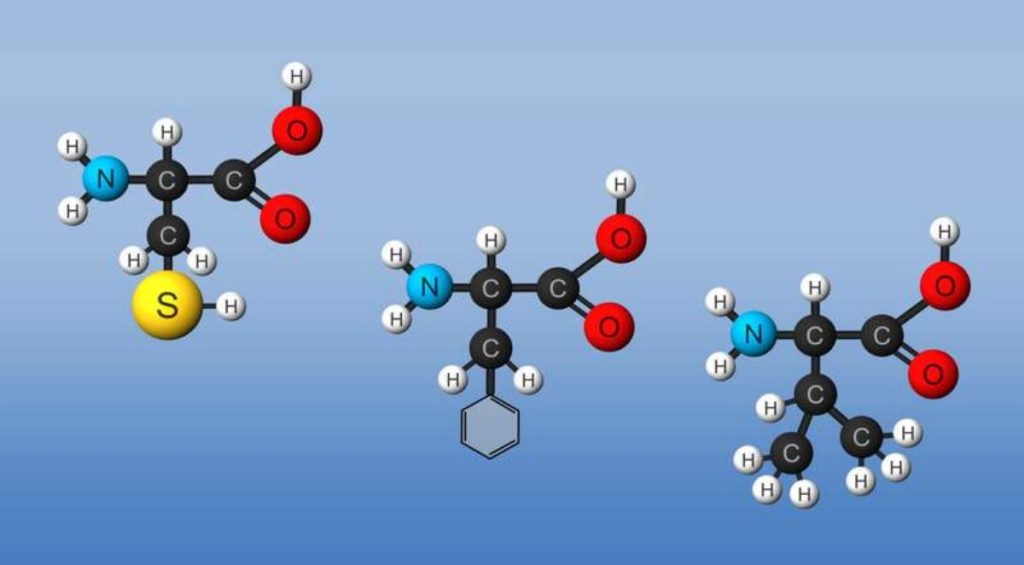
Amino acids form polymers through a nucleophilic attack by the amino group of an amino acid at the electrophilic carbonyl carbon of the carboxyl group of another amino acid. The carboxyl group of the amino acid must first be activated to provide a better leaving group than OH–. (We will discuss this activation by ATP later in the course.) The resulting link between the amino acids is an amide link which biochemists call a peptide bond. In this reaction, water is released. In a reverse reaction, the peptide bond can be cleaved by water (hydrolysis).
- Structure and Property of the Naturally-Occurring Amino Acids (Too large to include in text: print separately)
When two amino acids link together to form an amide link, the resulting structure is called a dipeptide. Likewise, we can have tripeptides, tetrapeptides, and other polypeptides. At some point, when the structure is long enough, it is called a protein. There are many different ways to represent the structure of a polypeptide or protein, each showing differing amounts of information.
Figure: Different Representations of a Polypeptide (Heptapeptide)
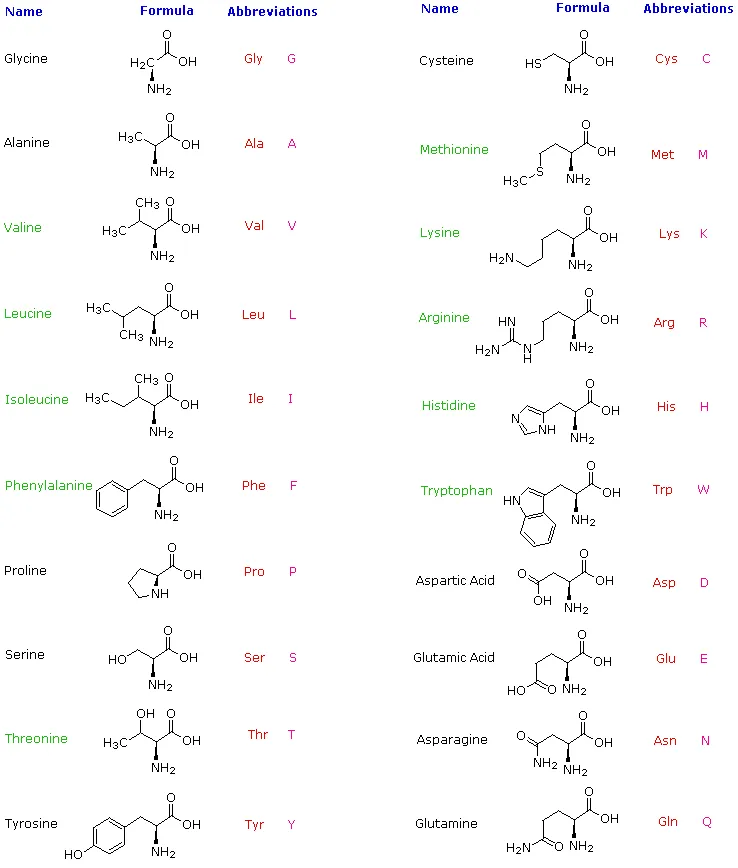
Figure: Amino Acids React to Form Proteins
(Note: above picture represents the amino acid in an unlikely protonation state with the weak acid protonated and the weak base deprotonated for simplicity in showing removal of water on peptide bond formation and the hydrolysis reaction.) Proteins are polymers of twenty naturally occurring amino acids. In contrast, nucleic acids are polymers of just 4 different monomeric nucleotides. Both the sequence of a protein and its total length differentiate one protein from another. Just for an octapeptide, there are over 25 billion different possible arrangements of amino acids. Compare this to just 65536 different oligonucleotides of 8 monomeric units (8mer). Hence the diversity of possible proteins is enormous.
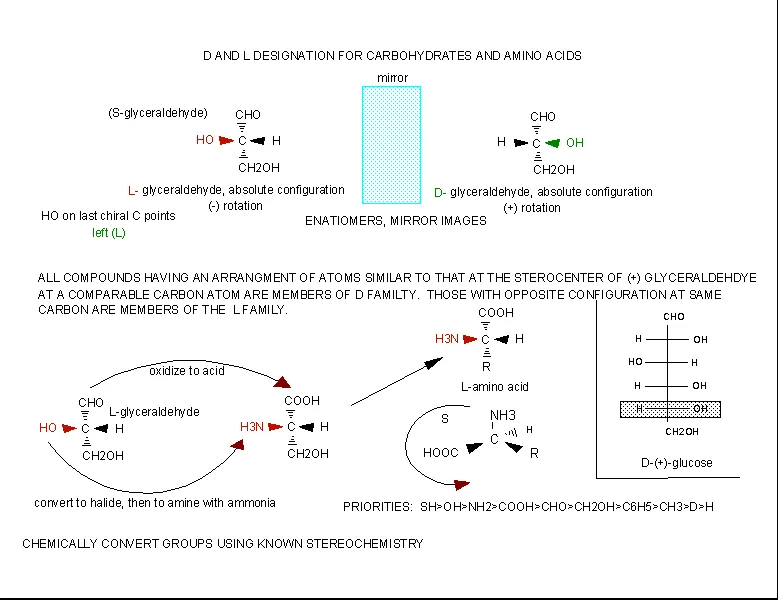
Stereochemistry
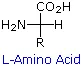
The amino acids are all chiral, with the exception of glycine, whose side chain is H. As with lipids, biochemists use the L and D nomenclature. All naturally occuring proteins from all living organisms consist of L amino acids. The absolute stereochemistry is related to L-glyceraldehyde, as was the case for triacylglycerides and phospholipids. Most naturally occurring chiral amino acids are S, with the exception of cysteine. As the diagram below shows, the absolute configuration of the amino acids can be shown with the H pointed to the rear, the COOH groups pointing out to the left, the R group to the right, and the NH3 group upwards. You can remember this with the anagram CORN.
Figure: Stereochemistry of Amino Acids.
Why do biochemists still use D and L for sugars and amino acids? This explanation (taken from the link below) seems reasonable.
“In addition, however, chemists often need to define a configuration unambiguously in the absence of any reference compound, and for this purpose the alternative (R,S) system is ideal, as it uses priority rules to specify configurations. These rules sometimes lead to absurd results when they are applied to biochemical molecules. For example, as we have seen, all of the common amino acids are L, because they all have exactly the same structure, including the position of the R group if we just write the R group as R. However, they do not all have the same configuration in the (R,S) system: L-cysteine is also (R)-cysteine, but all the other L-amino acids are (S), but this just reflects the human decision to give a sulphur atom higher priority than a carbon atom, and does not reflect a real difference in configuration. Worse problems can sometimes arise in substitution reactions: sometimes inversion of configuration can result in no change in the (R) or (S) prefix; and sometimes retention of configuration can result in a change of prefix.
It follows that it is not just conservatism or failure to understand the (R,S) system that causes biochemists to continue with D and L: it is just that the DL system fulfils their needs much better. As mentioned, chemists also use D and L when they are appropriate to their needs. The explanation given above of why the (R,S) system is little used in biochemistry is thus almost the exact opposite of reality. This system is actually the only practical way of unambiguously representing the stereochemistry of complicated molecules with several asymmetric centres, but it is inconvenient with regular series of molecules like amino acids and simple sugars. “
Natural α-Amino Acids
Hydrolysis of proteins by boiling aqueous acid or base yields an assortment of small molecules identified as α-aminocarboxylic acids. More than twenty such components have been isolated, and the most common of these are listed in the following table. Those amino acids having green colored names are essential diet components, since they are not synthesized by human metabolic processes. The best food source of these nutrients is protein, but it is important to recognize that not all proteins have equal nutritional value. For example, peanuts have a higher weight content of protein than fish or eggs, but the proportion of essential amino acids in peanut protein is only a third of that from the two other sources. For reasons that will become evident when discussing the structures of proteins and peptides, each amino acid is assigned a one or three letter abbreviation.
Natural α-Amino Acids
Some common features of these amino acids should be noted. With the exception of proline, they are all 1º-amines; and with the exception of glycine, they are all chiral. The configurations of the chiral amino acids are the same when written as a Fischer projection formula, as in the drawing on the right, and this was defined as the L-configuration by Fischer. The R-substituent in this structure is the remaining structural component that varies from one amino acid to another, and in proline R is a three-carbon chain that joins the nitrogen to the alpha-carbon in a five-membered ring. Applying the Cahn-Ingold-Prelog notation, all these natural chiral amino acids, with the exception of cysteine, have an S-configuration. For the first seven compounds in the left column the R-substituent is a hydrocarbon. The last three entries in the left column have hydroxyl functional groups, and the first two amino acids in the right column incorporate thiol and sulfide groups respectively. Lysine and arginine have basic amine functions in their side-chains; histidine and tryptophan have less basic nitrogen heterocyclic rings as substituents. Finally, carboxylic acid side-chains are substituents on aspartic and glutamic acid, and the last two compounds in the right column are their corresponding amides.
The formulas for the amino acids written above are simple covalent bond representations based upon previous understanding of mono-functional analogs. The formulas are in fact incorrect. This is evident from a comparison of the physical properties listed in the following table. All four compounds in the table are roughly the same size, and all have moderate to excellent water solubility. The first two are simple carboxylic acids, and the third is an amino alcohol. All three compounds are soluble in organic solvents (e.g. ether) and have relatively low melting points. The carboxylic acids have pKa‘s near 4.5, and the conjugate acid of the amine has a pKa of 10. The simple amino acid alanine is the last entry. By contrast, it is very high melting (with decomposition), insoluble in organic solvents, and a million times weaker as an acid than ordinary carboxylic acids.